
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ft_server
- FLIR
- 카메라
- 코멘토 후기
- 객체인식
- pseudo LiDAR
- miniRT
- 5월종합소득세
- 직무부트캠프
- 논문리뷰
- LIDAR
- 코멘토
- intrinsic
- extrinsic
- 머신비전
- AOLP
- ouster
- 42seoul #printf
- spinnaker
- superresolution
- 동시취득
- 의사 라이다
- 42seoul
- Python
- 삼쩜삼
- stereo image
- 편광카메라
- 라이다
- 3d object recognition
- point grey
- Today
- Total
문무겸비
super reolution 프로젝트 따라하기, Simulation-based Lidar Super-resolution for Ground Vehicles 리뷰 본문
super reolution 프로젝트 따라하기, Simulation-based Lidar Super-resolution for Ground Vehicles 리뷰
세월의 잔잔한 느낌 2022. 5. 31. 14:43LiDAR super resolution (라이다 해상도 upscaling 기술)
Simulation-based Lidar Super-resolution for Ground Vehicles

회사에서 라이다 데이터 수집을 자주 하면서, 라이다 센서의 활용성을 극대화 할 수 있는 기술은 어떤게 있을까 조사해보다가 point cloud 데이터에 대해 super resolution ai 기술을 적용할 수 있는 프로젝트(논문)을 찾게 되었다.
본 프로젝트는 16ch 같이 저해상도의 라이다 데이터를 64ch 고해상도 데이터로 upscaling(super resolution)해주는 AI와 관련되어있다. 이러한 기술을 통해 저가의 라이다로 고가의 라이다에 준하는 데이터를 구축할 수 있는 것이다.
현재 128ch 라이다로 자체 구축된 데이터도 많고, 논문 작성에 참고하기 좋을것 같아서 본 프로젝트를 구현해보고 자체적으로 구축한 데이터도 적용하기로 하였다.
window에서 ROS 설치 시도
https://jungreeyoung.tistory.com/3
ROS-WINDOW 10 환경에서 설치하기
윈도우 10부터는 ROS를 WINDOW환경에서도 사용가능해 졌습니다 이번에는 WINDOW 10 HOME에 ROS Noetic Ninjemys를 깔아보도록하겠습니다 출처:wiki.ros.org/ROS/Installation 를 가지고 진행하도록하겠습니다. R..
jungreeyoung.tistory.com
호환성 문제 해결
"현재 PC에서는 이 앱을 실행할 수 없습니다." 오류의 해결 방법
'현재 pc에서는 이 앱을 실행할 수 없습니다. pc 버전을 찾으려면 소프트웨어 게시자에게 문의하세요.' 실행하려는 파일에 문제가 발생한 경우 또는 적절한 파일이 아닌 경우에 이러한 오류 메시
itfix.tistory.com
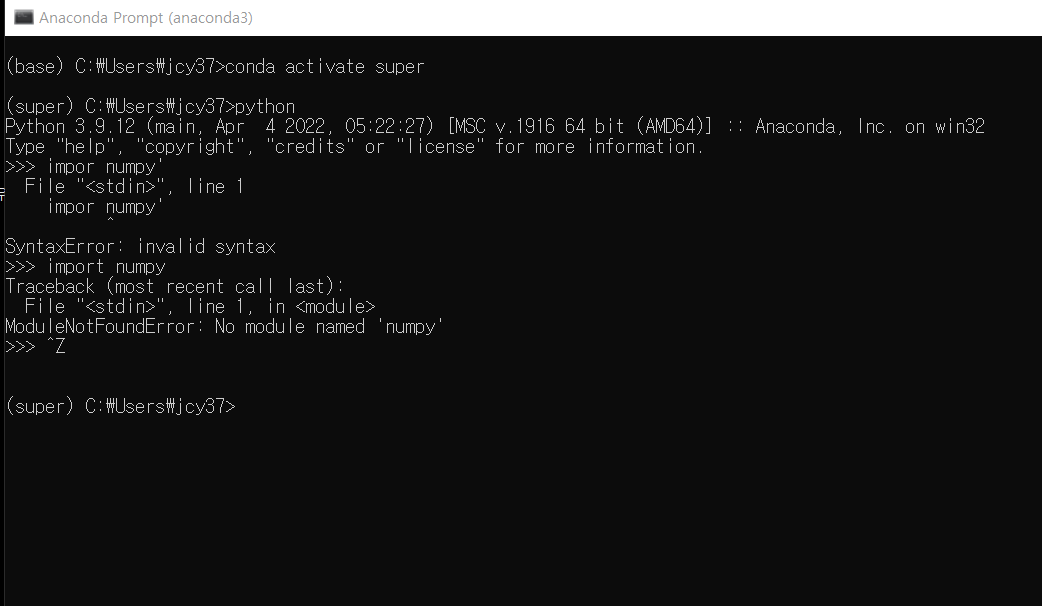
tensorflow 2.9(latest)를 사용하기 위해 numpy 1.2 이상이 필요했다
ros cmd에서 python 가상 환경을 사용할 때에는, 가상 환경 내에서 패키지 설치하면 안 됐다(ex. numpy) 근데 tensorflow는 깔린다
ros cmd - python 가상 환경에서는 cuda도 안 찾아진다
그래서 pycharm 가상환경에서 tensorflow 깔고, import 해봤는데 또 안된다
'''
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
'''
wsl 환경으로 넘어와서 진행하기로 결정
wsl2에서 cuda를 설치했다
WSL2 초간단 설치 및 CUDA(GPU) 설정 방법
그 동안 윈도우를 사용하며 맥으로 갈아탈까 고민하다가 남이있던 이유가 바로 WSL(Windows Subsystem for Linux) 때문이었다.사실 윈도우에서 개발을 한다는 것은 시간적, 정신적 에너지 소모가 크다고
velog.io
근데 nvidia-smi -q가 안 먹히더라.. 근데 nvidia-smi.exe -q는 먹힌다
nvcc --version도 먹힘
Why does nvidia-smi return "GPU access blocked by the operating system" in WSL2 under Windows 10 21H2
Installing CUDA on WSL2 I've installed Windows 10 21H2 on both my desktop (AMD 5950X system with RTX3080) and my laptop (Dell XPS 9560 with i7-7700HQ and GTX1050) following the instructions on http...
stackoverflow.com
wsl에서 cuda를 설치하기 위해서는 윈도우 버전 21050 이상이어야 한다. 근데 21050부터는 윈11이다. (21년 9월 작성 글 기준, 21년 12월 작성 글에서는 최근 업데이트를 통해 개선되었다고는 하나 글쎄...)
WSL2 딥러닝 환경 구축하기 (CUDA, CuDNN, Anaconda)
윈도우에서 강화학습 환경을 구축해보려고 했다. 하지만 환경 구축도 어려울뿐더러 구축되더라도 불편한 점이 너무 많았다. 깔끔하게 밀어버리고 우분투를 깔자니 윈도우를 버리면 포기해야할
medium.com
윈11로 넘어가기는 여러모로 불안하므로, wsl은 포기하고 docker로 넘어가자..
하기 전에 그냥 윈도우 환경에서 다시 한 번 해보기로 했다. ros는 포기하고. 학습부분만 돌려보기로...
할려다가 그냥 docker container linux로 학습도 하고 ros도 돌리는게 일원화에 도움이 될것 같아 그냥 docker로.
할려다가 window + docker + cuda는 없고 죄다 window + wsl2 + docker + cuda여서 안되는것으로 보인다. 포기
window 환경에서 학습을 우선 진행해보기로 하자. ros는 나중에. github 프로젝트 안에 Cmake이 있어 리눅스 환경 하에서만 되는 것처럼 느껴지긴 한데, 시각화에만 관련되어있는 것으로 보인다. 나중에 해보자 나중에. (window 용 cmake도 있고.. 뭐 어쨌든. catin_make는 ros 패키지 통합 관리를 위한 것이다. ros 깔면 내장되어 있는 듯 따로 깔 필요는 없다)
하는 도중에 "c\user\정찬영" 으로 되어있는걸 "c\user\jcy37" 로 바꿨다. 역시 한글로 경로 짜면 여러모로 불편하다(anaconda도 안되고 opencv도 못 읽고..)
https://zkim0115.tistory.com/1056
컴퓨터도 한번 밀었고, anaconda, 가상환경까지 적절하게 만들어졌으니 tensorflow랑 cuda 설치를 해보자
일단 cuda랑 tensorflow 안정적으로 설치 완료
python3.8
tensorflow=2.7
cuda=11.2
python의 os.systme() 은 cmd에 직접 입력하는 효과이다.
기존 model.py에 있던 killall 명령어는 linux에 명령어이이기 때문에 의미를 해석하여 window에 맞게 수정하였다.
os.system('taskkill /f /im tensorboard*')(수정 전, linux 버전)
os.system('killall tensorboard')window 버전의 경우 이렇게 하면 될 것으로 보인다. tensoboard와 관련된 프로세스는 다 종료!
근데 이럴 경우, 메세지가 한글로 설정되어있는데 반해, pycharm 콘솔에선 읽지를 못한다. 그래서 아래 코드를 추가하여 그냥 영어로 읽기로 했다.
os.system('chcp 65001')http://pertinency.blogspot.com/2019/11/pycharm-run-tool-window.html

근데 epoch이 돌아가는 것이 모니터링이 안된다. tensorboard도 먹통이고.

파란선 시점일 때, cmd 창에서 tensorboard taskkill 하니까 진행이 된다. tensorboard 프로세스가 진행되는 동안 get_model에서 빠져나오지 못하고 있다.(죽이니까 빠져나오긴 하는데 바로 프로그램 종료됨.)
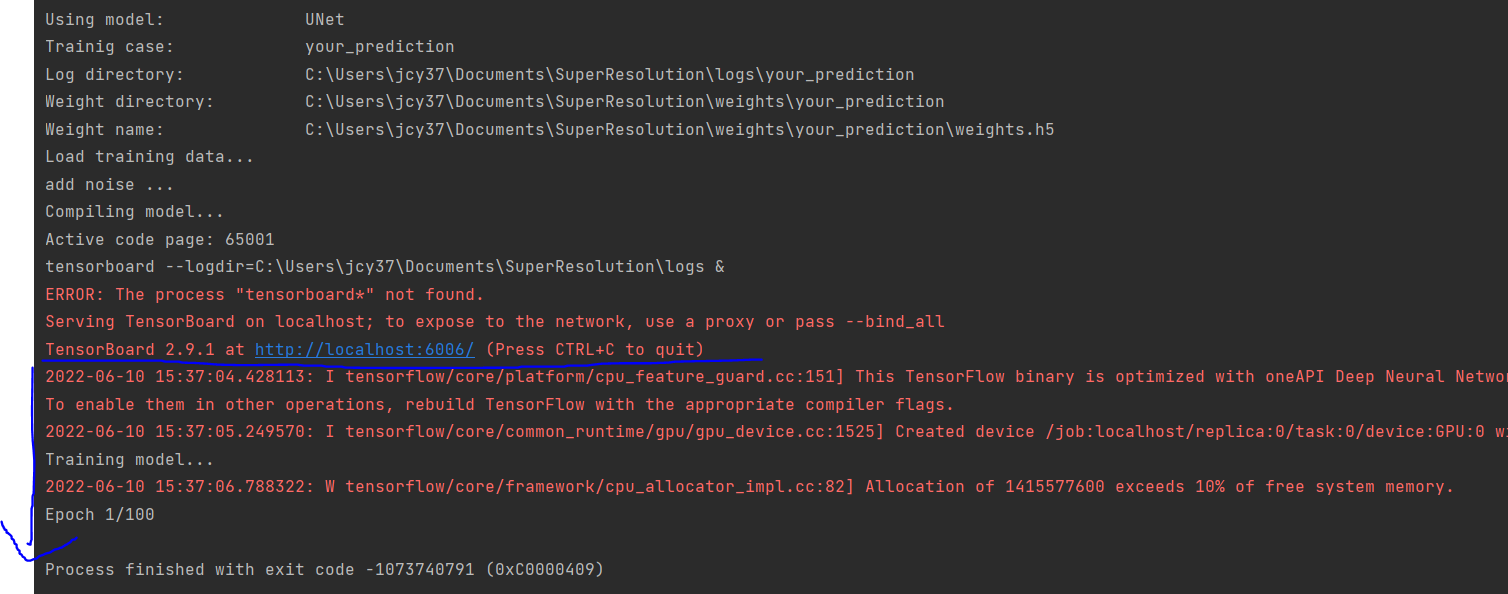
아래의 코드는 tensorboard를 실행시키는 명령어이다. 근데 리눅스 명령어가 좀 섞여있다. & 연산자는 명령어를 연달아 실행할 수 있게 삽입하는 건데, 앞쪽에 있는 명령어는 background에서 돌아가게 되어있다. 따라서 위 파란줄에 의해 정지되지 않고 쭉~ 진행될 수 있게 삽입한것으로 보인다. 그러나 윈도우에서는 요 기능을 하지 않기 때문에 코드를 아래와 같이 바꿨다. 윈도우에서는 앞쪽에 붙은 'start'가 background에서 동작하게 한다.
command = 'tensorboard --logdir=' + os.path.join(root_dir, 'logs') + ' &'
print(command)
os.system(command)(수정 전, linux 버전)
command = 'start tensorboard --logdir=' + os.path.join(root_dir, 'logs')
print(command)
os.system(command)(수정 후, windows 버전)
이제 잘 동작하긴 하는데.. tensorboard에서는 여전히 제대로 보이지가 않는다 ㅠㅠ 결국 epoch 1을 넘지 못하고 꺼졌다. 메모리 문제인가 역시.

리눅스 환경에서 코딩된 거 윈도우 환경에서 돌리려니 뭐가 문제인지도 모르겠다.. 그냥 리눅스 쓸걸 그랬나.
terminal에서 실행시키니까 또 다른 문제가 보인다. ㅋㅋ 오늘은 여기까지 해야지

cudnn 압축파일에서 모든 파일을 다 옮겨주면 해결되는 일이었다. 나는 cudnn_ops_64_8 인가? 요거 하나만 옮겨줘서 그랬다. 이 프로젝트에서는 모든 dll을 다 써서 다 옮겨주면 되는 듯하다.
문제가 잘 해결됐지만 GPU 메모리가 부족하여 실패.
linux에서 학습 시작
센터에서 소유하고 있는 워크스테이션을 통해 작업 재개. tesla v100 3개 장착되어있다 츄릅
환경은 우분투 20.
파이썬 가상환경을 이용하여 계속하였다.

cuda 설치 상태가 조금 의심스럽긴 한데.. 실제 동작은 문제없이 되는 것을 보니 다른 방법으로 이미 설치를 해놓은것 같다. cuda의 설치 위치가 아래 링크의 질문자와 매우 유사하다. 그래서 cuda가 제대로 설치 안됐다고 생각했는데, nvcc --version도 잘 나오고 해서 일단 묻어두고 진행. 문제는 없어 보인다.
https://forums.developer.nvidia.com/t/cuda-directory/70184
cuda 10.1
tensorflow 2.3
https://stackoverflow.com/questions/30866772/protocol-buffer-version-change
protobuf가 버전이 안 맞는 문제가 있었는데 위 링크 방법으로 해결했다. 가상환경이니까 다른 프로젝트에 영향이 갈 거 같진 않다.

간다.. 간다.. 돌아간다~~ 1분에 1 에폭쯤 된다
결과

텐서보드로 과거 학습결과 보는 법 (your_prediction 하위 폴더 train,test, .pb 파일 등등)
tensorboard --logdir=./your_prediction20 에폭 이후로는 거의 의미 없어 보인다.
demo data로 학습을 한번 따라해 봤으니, 이제 실제 데이터를 기반으로 모델을 돌려봐야겠다.
1.들어가는 데이터는 .npy 형식이니까, pcd 를 npy로 바꾸는 과정을 먼저 확인해봐야겠고.
시각화, ROS 시작
우선 시각화부터 해보자
시각화를 위해 ubuntu에 ros를 깔자.
http://wiki.ros.org/noetic/Installation/Ubuntu
noetic/Installation/Ubuntu - ROS Wiki
If you rely on these packages, please support OSRF. These packages are built and hosted on infrastructure maintained and paid for by the Open Source Robotics Foundation, a 501(c)(3) non-profit organization. If OSRF were to receive one penny for each downlo
wiki.ros.org
잘 깔다가 install에서 막혔다.
sudo apt install ros-noetic-desktop-full
에러 내용은 아래 링크의 질문자와 동일하다.
https://answers.ros.org/question/366280/error-installing-ros-noetic-in-ubuntu-20041-lts/
Error installing Ros Noetic in Ubuntu 20.04.1 LTS - ROS Answers: Open Source Q&A Forum
Error installing Ros Noetic in Ubuntu 20.04.1 LTS edit Dear friends, I'm having trouble installing ros on Ubuntu 20.04.1 LTS, my distro info: No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.1 LTS Release: 20.04 Codename: foca
answers.ros.org
아래 코드로 해결. "sudo apt install -f" maybe work too.
sudo aptitude install ros-noetic-desktop-fullhttps://devanix.tistory.com/224
[Chap2 #05] - aptitude를 사용하여 Software 관리
♧ dpkg와 APT는 오랫동안 사용되어 온 훌륭한 도구지만, 이들 도구는 여러 측면에서 미묘한 차이를 가지고 있기 때문에 제대로 사용하기 위해서는 상당한 이해가 요구된다. aptitude 프로그램은 curs
devanix.tistory.com

ros에서 제공해주는 tutorial로 기본적인 사용방법과 catkin_make를 시도.
http://wiki.ros.org/ROS/Tutorials/CreatingPackage
ROS/Tutorials/CreatingPackage - ROS Wiki
Using roscreate Before we create a package, let's see how the roscreate-pkg command-line tool works. This creates a new ROS package. All ROS packages consist of the many similar files : manifests, CMakeLists.txt, mainpage.dox, and Makefiles. roscreate-pkg
wiki.ros.org
catkin workspace는 root에 있어야 한다.
https://answers.ros.org/question/252980/catkin_make-fail-must-be-invoked-in-the-root-of-workspace/
catkin_make fail : must be invoked in the root of workspace - ROS Answers: Open Source Q&A Forum
catkin_make fail : must be invoked in the root of workspace edit Please... Please help. I am trying to use rplidar, but I have this error below......... I checked the tutorial again and again but I really don't know how to fix this.. Please help me. ubuntu
answers.ros.org
ros package 이름이 좀 안 맞는 거 같아 github에 issue 올림.
https://github.com/RobustFieldAutonomyLab/lidar_super_resolution/issues/10
Is ros package dependancy 'sensors_msgs" right? · Issue #10 · RobustFieldAutonomyLab/lidar_super_resolution
I made ad added 'lidar-super_resolution' package to visualizing result. but there are problem "non-existent package 'sensors_msgs'. I think that will be 'sensor_msgs'. ...
github.com
제대로 한건진 모르겠지만, dependent 한 패키지 이름도 임의로 수정해서 'lidar_super_reolution' package를 catkin_make 하였다.
그리고
roslaunch lidar_super_resolution visualize.launch요걸 동작시켰는데 잘 안 된다. 동작한 위치가 잘못된건지.. 아니면 처음부터 그냥 잘못된건지.. 분간이 잘 안된다. 일단 오늘은 여기까지.
deep@deep-SYS-7049GP-TRT:~/Downloads/lidar_super_resolution-master/launch$ roslaunch lidar_super_resolution visualize.launch
RLException: [visualize.launch] is neither a launch file in package [lidar_super_resolution] nor is [lidar_super_resolution] a launch file name
The traceback for the exception was written to the log file
ros 튜토리얼에 따르면, launch 파일은 패키지 폴더 안에 있어야 한다. 내일은 visualize.launch 파일을 lidar_super_resolution 패키지 폴더 안에 넣어봐야지.
ROS/Tutorials/UsingRqtconsoleRoslaunch - ROS Wiki
Please ask about problems and questions regarding this tutorial on answers.ros.org. Don't forget to include in your question the link to this page, the versions of your OS & ROS, and also add appropriate tags. Using rqt_console and roslaunch Description: T
wiki.ros.org
visualize.launch->visualize.rviz->numpy2cloud.py 다 패키지 안 폴더에 넣어놨다. (화살표 방향대로 참조)
하지만 에러가 발생

Crytodome 패키지가 제대로 설치가 안되어서 생긴 문제로 보인다. 이 시점에서, 가상 환경에서 계속 진행해야겠다는 판단을 했고, 가상환경 하에서 코드를 돌렸다.
가상환경에서는 rospkg, cryptodome, gnupg 패키지가 없다고 차례대로 오류가 나왔으며, 다 설치했다.
pip install rospkg
pip install pycryptodomes
pip install gnupg
성공하긴 했는데.. 왜 이 모양 인지 모르겠다 성공하긴 했는데.. 굳이 rivz로 시각화를 해야 할 필요가 있는가?라는 의문이 조금 든다. 일단 github에서 제공한 학습-시각화라는 과정은 모두 성공했다

npy 파일도 보아하니 그냥 pcd 파일이더라. 이거를 직접 load, python에서 시각화를 하는 것이 나을 것 같다.
matplotlib으로는 좀 어려울 거 같아서.. python용 3d 시각화 패키지가 좀 필요할 거 같다. 아래는 시각화 패키지 설치법
https://pcl.gitbook.io/tutorial/appendix/visualization
시각화Code - Tutorial
def draw_lidar(pc, color=None, fig=None, bgcolor=(0,0,0), pts_scale=1, pts_mode='point', pts_color=None): if fig is None: fig = mlab.figure(figure=None, bgcolor=bgcolor, fgcolor=None, engine=None, size=(1600, 1000)) mlab.points3d(pc[:,0], pc[:,1], pc[:,2],
pcl.gitbook.io
point cloud 시각화가 좀 이상하게 돼서 무슨 문젠가 했더니 각도가 radian이 아니라 degree로 처리되고 있었다.. numpy 낮은 버전에서는 삼각함수가 degree로 처리된 건가..??

문제점이 드러났다.
첫째로, ouster OS2 128ch은 레이저 배열 모양이 일직선이 아니다. 가로방향은 일직선이되, 세로 방향의 경우 레이저 4개마다 각도가 반복된다
0 ^ 0 ...
0 ^ 0...
0 ^ 0....
0 ^ 0....
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0...
0 ^ 0....
요런 느낌이랄까. 각 각도의 차이는 1.38도 정도. 이러니 바로 위의 레이저가 실제 좌표에서 바로 위의 정보를 반영하지 못한다...
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0 ...
0 ^ 0 ...
이 문제를 피하기 위해, 128ch 중 32ch만 사용해야 할 것 같다. 그럼 8ch ->32ch super resolution 하고 실제 데이터랑 비교하는 걸로..? 코드상에서는 별 문제없이 수정이 가능한것으로 보인다.
둘째로, point cloud 데이터에서는 각 point가 어느 채널, 어느 azimuth에서 나왔는지 파악이 어렵다. 따라서 raw 데이터에서 다시 pcd 파일을 뽑아내야 할 듯하다
1.point cloud 추출할 때 32 * 1024 형태로 뽑으면 되겠다.
2. 반올림 코드 없애기(정밀성을 위해) -> vertical 각도가 좀 이상해서 이게 문제인줄 알았는데, 그렇게 큰 문제는 아닌듯
3. rm_zero_point 함수 없애기 (포인트 개수, 포인트->픽셀 매핑 확인을 위해)
os2 스펙상 VFOV는 -11.25 ~ 11.25 (25도) 인데, 실제로는 다르다. 센터가 소유한 모듈의 경우, -11.51 ~ 10.16(21.67도 이고) 각 행간 각도도 다 조금씩 다르다.
실제 라이다(센서) 제작 후, 캘리브레이션을 거쳐 실제 VFOV, 각 간격을 정한다고 한다. 스펙은 그냥 스펙일 뿐. 따라서 라이다 마다 조금씩 다르다.(각 라이다 마다 pcd 추출 코드 변경해야겠다...)
그러나 실제 자세한 vertical angle은 중요한건 아닌거 같다 어차피 2d 이미지 픽셀에 매핑할테니까
향후 진행 방법으로는,
1. 기존 라이다 백업 데이터 이용해, 32ch 데이터 뽑아내서 npy file로 만들기.5000set 정도.
2. 8ch -> 32ch super resolution 모델 돌리기
3. 결과 평가하기.

결과 파일에는, point cloud 데이터가 아니라 mean, var 데이터가 저장되어 있다.

train 4000 frame - test 429 frame을 32ch to 128ch 학습을 30에폭으로 돌려 봤다. 문제가 있을거라 생각했는데 생각보다 잘 돌아가더라.

model.fit 의 validation_split 인자는 주어진 train data 중에서 validation data를 얼마만큼의 비율로 할것인지의 값이다.




octomap은 라이브러리다. https://octomap.github.io/
OctoMap - 3D occupancy mapping
OctoMap An Efficient Probabilistic 3D Mapping Framework Based on Octrees The OctoMap library implements a 3D occupancy grid mapping approach, providing data structures and mapping algorithms in C++ particularly suited for robotics. The map implementation i
octomap.github.io

자체적으로 수집한 OS2-128로 학습, 평가한 결과(학습데이터 4,000, 평가데이터 429) 위와 같은 결과가 나왔다.
평가데이터가 후반부에 문제가 있는 점 때문에 407번째 데이터까지만 평가하였다.
라이다 센서 정렬이 일직선이 아니라는 점이 데이터 학습에 영향을 준것처럼 보인다. 채널 배열이 바뀌는 시점에서 smoothing이 일어나는 것처럼 보인다(4ch마다).
removed percentage가 매우 크다. 30 epoch밖에 안해서, 채널의 배열, 데이터의 품질 등이 영향을 끼쳤을것으로 보인다.
Validation이 train보다 loss가 적게 나오는 이유
학습데이터셋의 후보는 다음과 같다
2022년
1. 2022년도 데이터는 지그에 의해 가려진 부분이 있어서 360도 데이터가 온전히 있지 않다. -> 지그 부분을 잘라내어 없는셈 치면 커버 가능
2. 2022년도 데이터는 날씨, 시간대, 도로 유형이 다양하지 않다. -> 아주 부족하지는 않다, 그리고 정제된 부분이 별로 적은 것 뿐이지, 부족한 데이터를 일일히 골라내면 충분히 채울 수 있을듯
2021년
1. 2021년도 데이터는 3d bbox인데 반해, 2022년도는 segmentation이다.
2. 2021년도 데이터는 라이다 품질이 비교적 좋지 않다.
일단 최근 데이터 기준으로 하는게 더 좋기도 하고, segmentation이 좀 더 많은 연구 결과를 뽑아낼 수 있지 않을까? 우선 2022년도 데이터 기준으로 진행하자
10,000셋 학습, 3000셋 테스트로 만들자.
ILN 모델도 돌리기 위해 가상환경이 계속 필요하다. python 버전도 바꿔야 하는 상황이기에, venv가 아닌 virtualenv를 추가로 설치하자
sudo apt install python3-pip
sudo apt install virtualenv (or pip3 install virtualenv)
sudo apt update (아래 줄 명령어가 안먹혀서)
sudo apt install python3.8
virtualenv --python=python3.8 iln
source iln/bin/activate
https://svrforum.com/svr/43553
서버포럼 - 리눅스 패키지설치시 E: Unable to correct problems, you have held broken packages. 에러 해결방법
안녕하세요. 달소입니다. 오늘은 ubuntu에서 패키지 설치시 나오는 E: Unable to correct problems, you have held broken packages. 가 나왔을때 해결하는 방법입니다. 해당 에러는 패키지 리스트가 꼬여서 발생하
svrforum.com
https://doongdangdoongdangdong.tistory.com/247
Python 가상환경 (virtualenv) 생성 및 실행하기
◽Ubuntu 20.04 (Linux) ◽Python3의 기본환경에서 Python2.7(+ python2에 맞는 pip2 설치)를 가상환경으로 만들어주고 싶다. ✍️ Python 가상환경 virtualenv 생성하기 Python과 PIP3가 설치되어 있는 상태에서 virtuale
doongdangdoongdangdong.tistory.com
implicit lidar 프로젝트를 ros package로 등록하려면 아래 github 과정을 따라가면 된다.
https://gist.github.com/rebeccali/a1d93128c892e677f3a2f40c8e6f38d9
source /opt/ros/kinetic/setup.bash
source ~/catkin_ws/devel/setup.bsh
cd ~/catkin_ws
catkin_makehttps://gist.github.com/rebeccali/a1d93128c892e677f3a2f40c8e6f38d9
Installing ROS packages from external source
Installing ROS packages from external source. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
ros package는 등록했는데, 동작도 되는데, 별 의미가 없는거 같기도.. input을 msg로 넣어줘야하는데 방법을 모르겠다.
(demo_lidar_super_resolution_ros.py)
일단 demo_lidar_image_super_resolution.py 코드를 실행해 보았다. 프로젝트에서 제공해주는 rimg 파일을 이용해서 super resolution 결과를 내어준다. trained weight 를 이용한다. rimg는 pointcloud 데이터를 range img화 해서 저장한 ndarray 형식. 아래 코드는 rimg를 읽는 함수이다.
def read_range_image_binary(filename, dtype=np.float16, lidar=None):
"""
Read a range image from a binary file.
:param filename: filename of range image
:param dtype: encoding type of binary data (default: float16)
:param lidar: LiDAR specification for crop the invalid detection distances
:return: range image encoded by float32 type
"""
range_image_file = open(filename, 'rb')
# Read the size of range image
size = np.fromfile(range_image_file, dtype=np.uint, count=2)
# Read the range image
range_image = np.fromfile(range_image_file, dtype=dtype)
range_image = range_image.reshape(size[1], size[0])
range_image = range_image.transpose()
range_image = range_image.astype(np.float32)
if lidar is not None:
# Crop the values out of the detection range
range_image[range_image < 10e-10] = lidar['norm_r']
range_image[range_image < lidar['min_r']] = 0.0
range_image[range_image > lidar['max_r']] = lidar['norm_r']
range_image_file.close()
return range_image.astype(np.float32)
AI 모델 학습 결과

이전에 할때는 오차가 커서 문제였는데, 이제는 학습이 이상하게 되고 있다.


pre trained 모델을 시험삼아 돌려봤을 때는 944 columns의 데이터라도 잘 돌아가는 걸 확인했지만, 내가 학습한 모델로 돌리면 잘 안된다.
1. 양쪽에 빈공간이 생긴게 문제일 수도 있고
2. 1024 같은 딱 맞아 떨어지는 채널 수가 아닌게 문제일 수도 있다.
아무래도 양쪽에 빈공간이 문제가 아닐까 싶다
빈공간이 문제라고 생각하여, 944열에서 912열로 양 쪽을 잘랐다. (기존에는 924열이었는데, 8로 안나누어져서 944열로 빈데이터를 집어넣었던 것임)
912열로 데이터 만들것을 10epoch 돌린 결과이다

100epoch 결과이다. l1 loss는 줄어든 반면에 removed point는 일부 증가하였다.


100epoch 짜리가 이번에 한것이고, 30epoch짜리는 예전에 다른 데이터로, 채널 수정 없이 학습한 결과이다. 유의미한 차이가 보인다.
MC dropout
Mc-dropout (몬테카를로 드롭아웃)은 본 논문에서 사용된 방법이다
https://dodonam.tistory.com/341
드롭아웃(dropout), 몬테 카를로 드롭아웃(Monte Carlo dropout)
드롭아웃(dropout) 드롭아웃 : 심층 신경망에서 가장 인기있는 규제 기법 중 하나 (2012년 제프리 힌턴이 제안) - 매 훈련 스텝에서 각 뉴런은 임시적으로 드롭아웃될 확률 p를 가짐 (인풋 뉴런 포함,
dodonam.tistory.com
드롭아웃(dropout)
드롭아웃 : 심층 신경망에서 가장 인기있는 규제 기법 중 하나 (2012년 제프리 힌턴이 제안)
- 매 훈련 스텝에서 각 뉴런은 임시적으로 드롭아웃될 확률 p를 가짐 (인풋 뉴런 포함, 아웃풋 뉴런 제외)
- 훈련이 끝난 후 예측 과정에서는 드롭아웃을 적용하지 않음
- 드롭아웃을 이용해서 모델의 정확도를 2~3% 더 올렸다는 연구는 매우 흥미로움

주의할점
> p=50%로 설정되었을때, 특정 뉴런은 평균적으로 두배 많은 입력과 연결되므로, 이런 부분을 보정하기위해, 훈련이 끝난 이후, 연결 가중치에 0.5를 곱함
> 즉, 훈련이 끝난 뒤, 연결 가중치에 보존 확률 (1-p)를 곱한다.
몬테 카를로 드롭아웃 (Monte Carlo dropout)
- 야린 갤과 주빈 가라마니의 2016년 논문에서 드롭아웃을 사용해야할 이유
1. 드롭 아웃을 수학적으로 정의하여 드롭아웃 네트워크와 근사 베이즈 추론 사이에 깊은 관련성 정립
2. 드롭아웃 모델을 재훈련하거나 전혀 수정하지 않고, 성능을 크게 향상시킬 수 있는 몬테 카를로 드롭 아웃 소개
몬테 카를로 드롭아웃 방법
- 예측과정에서 일반 dropout기법과 다르게 dropout층을 활성화 시키고, 테스트 셋의 100번 예측 결과를 만듦
- 드롭아웃으로 만든 예측을 평균하면 일반적으로 드롭아웃이 없이 예측한 하나의 결과보다 더 안정적인것 확인
논문 투고
2023 하계전자공학회 투고 및 oral presentation까지 완료했다.

비정형 라이다 채널 변환이란, 위에서 언급한 바와 같이 OS2 lidar의 문제인 채널 배치를 데이터 상에서 변환하여 super resolution 모델에 적용할 수 있게 하는 것이다


유형별 분석에서, 날씨/시간대/도로유형에 따라 superresolution 성능을 비교하였다.
자전로, 야간, 맑음에서 수치가 낮은 경향을 보여주을 알 수 있다




회고
ROS에 대한 이해를 가질 수 있었으며
기존 딥러닝 모델 적용을 오롯이 처음부터 끝까지 해낼 수 있었다
또한 자력으로 혼자서 논문 작성을 처음부터 끌까지 해낼 수 있었다
역시 환경 구성이 제일 어려웠지만 하면 할수록 비슷한 방식으로 해결이 가능하다는 것을 깨달을 수 있어다
'개인공부' 카테고리의 다른 글
| PCL (point cloud library) 뜯어보기 (0) | 2023.01.11 |
|---|---|
| 편광카메라 이미지 분석 (0) | 2022.12.09 |
| PCD 파일 data type converter (0) | 2021.09.08 |
| velodyne LiDAR puck 패킷 분석 및 viewer 프로그래밍 (2) | 2021.09.03 |
| [논문리뷰] 카메라로 라이다를 만들 수 있다고? "Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving" (1) | 2021.05.19 |


